In part three of my XKCD font saga I generated several hundred glyphs as PPM images, and classified them with their associated character(s). In this instalment, I will convert the raster glyphs into vector form (SVG) and then generate a rudimentary font using FontForge.
If you'd like to follow along, the input files for this article may be found at https://gist.github.com/pelson/1d6460289f06acabb650797b88c15ae0, while the code (in notebook form) and output may be found at https://gist.github.com/pelson/18434e3bd37dcde8dd28a5a24def0060.
I make no apologies for the amount of code here - I've tidied it up a little, but it is representative of the journey I have taken to produce a fully functional XKCD font. If you just want to see the resulting font you can scroll about three-quarters of the way down the page to play with the final font in your browser.
Raster to Vector conversion (PPM to SVG)¶
The glyph images that need SVG vectorisation are simple black and white images, so this falls well into the realm of potrace and autotrace.
I notice that bioconda has a potrace binary, so I use conda to install it. There are python bindings for potrace, but really we just want to convert one filename into another filename, so I'll just call out to the system.
import subprocess
def potrace(input_fname, output_fname):
subprocess.check_call(['potrace', '-s', input_fname, '-o', output_fname])
import os
import glob
for fname in glob.glob('../xkcd_font_stroke_classification/char_*.ppm'):
new_name = os.path.splitext(os.path.basename(fname))[0] + '.svg'
potrace(fname, new_name)
Just to confirm this is as we expected, I'll take a look at one of the newly vectorised SVGs. The slight complexity here is that IPython.display doesn't support the ppm format, so I need to load the ppm image with PIL/Pillow, and convert it to PNG (without creating a temporary file) before doing the standard IPython image display trick.
import PIL.Image
from io import BytesIO
from IPython.display import SVG, Image, display, Markdown
ppm_sample = '../xkcd_font_stroke_classification/char_L2_P2_x378_y1471_x766_y1734_a-s_0x61-0x73.ppm'
svg_sample = 'char_L2_P2_x378_y1471_x766_y1734_a-s_0x61-0x73.svg'
im = PIL.Image.open(ppm_sample)
png_img = BytesIO()
im.save(png_img, 'PNG')
png_img.seek(0)
display(Markdown('#### Raster version (PPM, original pixel resolution)'))
display(Image(data=png_img.read()))
display(Markdown('#### Vector version converted from PPM to SVG with potrace'))
display(SVG(filename=svg_sample))
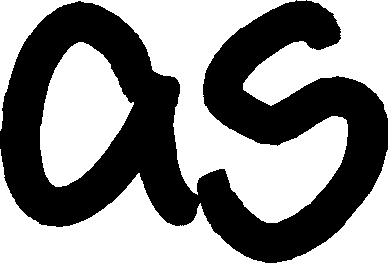

Naturally, the vectorisation has smoothed some of the edges - I just used the default settings and I think the results are pretty pleasing. We now have glyphs that scale extremely well (much better than the rasterised form), and in this instance just so happen to be around 75x smaller in filesize!
!du -h $ppm_sample $svg_sample
Creating a font from SVGs using fontforge¶
Now that I have all of the glyphs in vector form, I'm going use fontforge to create a font with glyphs imported from the appropriate SVG shapes.
Finding a build of fontforge with python bindings that could be used in my environment proved to be a challenge, so I ended up compiling fontforge myself. On OSX the build followed a fairly standard pattern:
export PREFIX=/Users/pelson/miniconda/envs/fontforge
git clone git@github.com:fontforge/fontforge.git
cd fontforge && git checkout 20161012
# Install some of font-forge's dependencies (I'm confident that there are others that are already
# on my system, so better isolation would be needed to turn this into a proper conda-forge recipe).
conda create -c conda-forge python=2.7 pango glib freetype libxml2 pkg-config -p ${PREFIX}
source activate ${PREFIX}
# Bootstrap the compilation. This eventually calls auto(re)conf.
./bootstrap --force
# Tell fontforge where it can find PANGO.
export PANGO_CFLAGS=-i${PREFIX}/include/pango-1.0
export PANGO_LIBS=-lpango-1.0
# Turn off the X11 interface - we just want the python package.
./configure --prefix=${PREFIX} --without-x --without-cairo
make
make install
You may notice that I forced the version back to python 2.7. It was a shame to have to use a legacy python version, but I was having issues with FontForge's creation of lookuptables with python 3.5+.
Unfortunately, this does mean I'm going to have to manually deal with "wide" unicode characters. At the time of writing conda only provides narrow python 2 build, which means it doesn't deal well with characters outside of unicode's "basic multilingual plane". Python 3.5+ completely did away with the "narrow" vs "wide" python concept and therefore the need to recompile python in order to natively handle some unicode characters properly!
Some more detail on wide vs narrow can be found at https://www.python.org/dev/peps/pep-0261/ and http://wordaligned.org/articles/narrow-python.
The best place I can find the python 3.5+ improvement documented is in Nick Coghlan's blog about why python 3 is better than python 2 out of the box.
In particular, with a narrow python build (i.e. a version before python 3.5 that has been compiled with the default settings) the following will occur:
$ python2
Python 2.7.12 | packaged by conda-forge | (default, Sep 8 2016, 14:41:48)
>>> print(u'🎂')
🎂
>>> print(ord(u'🎂'))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: ord() expected a character, but string of length 2 found
To repeat myself, the fix for this kind of issue is one of the following:
- recompile python in "wide" mode
- upgrade to python 3.5+
- deal with the special case in your code
In my situation, the first option would be a burden, the second option was not possible due to the fontforge bug mentioned above, so I'm forced with option 3: deal with the special case in my code.
With the above complete, I can now import fontforge and continue the saga...
import fontforge
fontforge.__version__
I start by getting hold of the metadata from my SVG files.
import os
import glob
import parse
fnames = glob.glob('char_*.svg')
characters = []
for fname in fnames:
# Sample filename: char_L2_P2_x378_y1471_x766_y1734_a-s_0x61-0x73.svg
pattern = 'char_L{line:d}_P{position:d}_x{x0:d}_y{y0:d}_x{x1:d}_y{y1:d}_{char}_{hex_repr}.svg'
result = parse.parse(pattern, os.path.basename(fname))
# Split the hex representation by the "-" separator and convert to unicode ordinals.
ords = [int(hex_char, 16) for hex_char in result['hex_repr'].split('-')]
# Now, where possible, generate character glyphs.
# In python 3.5+ this would be so much more pleasant.
chars = tuple(unichr(ordinal) if ordinal < 65536 else ordinal
for ordinal in ords)
# Let's deal with that second I variant that has the two crosses - typically used for I as a
# pronoun.
if len(chars) > 1 and ''.join(chars) == 'I-pronoun':
chars = tuple(' I ')
bbox = (result['x0'], result['y0'], result['x1'], result['y1'])
characters.append([result['line'], result['position'], bbox, fname, chars])
First attempt¶
Because the handwriting sample included a few paragraphs, we have several characters which are repeated - eventually it would be great to use all of the information as single alternates withing the font, so that I get variation on glyphs (I haven't checked that this is a real thing, but it sounds like it should be).
For now though, just use the first instance of each character. I'll also use the first instance of each ligature (those glyphs, such as TT, that I couldn't separate in the previous installments).
First, set up the font globals:
def basic_font():
font = fontforge.font()
font.familyname = font.fontname = 'XKCD'
font.encoding = "UnicodeFull"
font.version = '1.0';
font.weight = 'Regular';
font.fontname = 'XKCD'
font.familyname = 'XKCD'
font.fullname = 'XKCD'
font.em = 1024;
font.ascent = 768;
font.descent = 256;
# We create a ligature lookup table.
font.addLookup('ligatures', 'gsub_ligature', (), [[b'liga',
[[b'latn',
[b'dflt']]]]])
font.addLookupSubtable('ligatures', 'liga')
return font
Now I want to create each of the glyphs from our SVG images. This requires a call such as:
c = font.createMappedChar(unicode_ordinal)
c.importOutlines(svg_filename)
Unfortunately, FontForge can't currently deal with unicode filenames for its import (issue 3058), so I make a context manager that creates temporary non-unicode filenames that are just symlinks to the original file.
from contextlib import contextmanager
import tempfile
import shutil
import os
@contextmanager
def tmp_symlink(fname):
"""
Create a temporary symlink to a file, so that applications that can't handle
unicode filenames don't barf (I'm looking at you font-forge)
"""
target = tempfile.mktemp(suffix=os.path.splitext(fname)[1])
fname = os.path.normpath(os.path.abspath(fname))
try:
os.symlink(fname, target)
yield target
finally:
if os.path.exists(target):
os.remove(target)
Finally, I'm ready to start adding glyphs to my font. I track which ones I've added to avoid adding multiple versions of glyphs that have already been seen.
def create_char(font, chars, fname):
if len(chars) == 1:
# A single unicode character, so I create a character in the font for it.
# Because I'm using an old & narrow python (<3.5) I need to handle the unicode
# characters that couldn't be converted to ordinals (so I kept them as integers).
if isinstance(chars[0], int):
c = font.createMappedChar(chars[0])
else:
c = font.createMappedChar(ord(chars[0]))
else:
# Multiple characters - this is a ligature. We need to register this in the
# ligature lookup table we created. Not all font-handling libraries will do anything
# with ligatures (e.g. matplotlib doesn't at vn <=2)
ligature_name = '_'.join(chars)
ligature_tuple = tuple([character.encode('ascii') for character in chars])
c = font.createChar(-1, ligature_name)
c.addPosSub('liga', ligature_tuple)
c.clear()
# Use the workaround to have non-unicode filenames.
with tmp_symlink(fname) as tmp_fname:
# At last, bring in the SVG image as an outline for this glyph.
c.importOutlines(tmp_fname)
return c
font = basic_font()
visited = []
for line, position, bbox, fname, chars in characters:
if chars in visited:
# We have already seen this set of chars. For now, I do nothing
# with duplicates.
continue
visited.append(chars)
c = create_char(font, chars, fname)
So it seems I have now created the appropriate FontForge font. I want to test this in a tool that can display fonts well. As it happens, I'm using jupyter notebook, which is browser based. Browsers display fonts well. Let's target that using the Web Open Font Format.
Creating a woff with FontForge is as easy as:
font.generate('xkcd.woff')
Now I need to do some magic to use the font in the notebook...
I use IPython's display functionality to embed HTML directly in the notebook:
- The HTML will essentially be the appropriate CSS directives to make use of the woff I just created.
- In order to ensure the woff can be enjoyed by everybody, I embed the font as a base64 object directly in the CSS (the same trick that Jupyter notebooks use for images).
- I'm going to iterate a few times on this font, so I get a unique handle to this font within my CSS by adding a uuid component to the IDs.
- I'll do some fancy things to allow you, the reader, to type whatever you like and see the results.
import uuid
import base64
import textwrap
from IPython.display import display, HTML
def preview_font(fname, content, unique_id=None):
if unique_id is None:
unique_id = uuid.uuid4()
with open(fname, 'rb') as fh:
woff_base64 = encoded_string = base64.b64encode(fh.read())
html = u"""
<style>
@font-face {{
font-family: xkcd-{uid};
src: url('data:font/opentype;base64,{woff_base64}') format('woff');
}}
.XKCD-{uid} {{
font-family: xkcd-{uid};
font-size: 2em;
color: black;
line-height: 150%;
white-space: pre;
}}
</style>
<a name="font-{uid}"></a>
<textarea id="input-{uid}" style="width: 60%; min-width: 20em; height: 6em;">{content}</textarea>
<div id="content-{uid}" class="XKCD-{uid}"></div>
<script>
function update_content() {{
document.getElementById("content-{uid}").textContent = document.getElementById("input-{uid}").value;
}}
document.getElementById("input-{uid}").addEventListener('input', update_content);
update_content();
</script>""".format(uid=unique_id, woff_base64=woff_base64, content=content)
font_preview = HTML(html)
return font_preview
font_fname = 'xkcd.woff'
display(preview_font(font_fname, content="Hello world - this is my first attempt.\nLigature: BETTER"))
For a first attempt, it's not terrible (well, I can read it)... though there are clearly some pretty fundamental issues here.
If you haven't already done so, have a play with the text area to get a feel for the font that has been created.
The biggest issue is with the scaling of the glyphs (as highlighted by the comical period). It seems that when FontForge imports the SVGs, it scales the image to the size of the glyph being created - this isn't really the behaviour I want, as my images are already scaled appropriately. I'm going to need to get hold of the glyphs bounding box and scale the resulting geometries using fontforge's inbuilt affine matrix package psMat.
Some documentation on the python interface, particularly the Glyph class, can be found at https://fontforge.github.io/python.html#Glyph. It isn't the most comprehensive documentation, and in reality, I will probably need to experiment somewhat.
In this instance it was convenient to create a web open font format directly, but it is equally possible to write directly to the OTF or TTF formats with:
font.generate('xkcd.otf')
font.generate('xkcd.ttf')
Scaling the glyphs¶
In order to scale the glyphs I will need to be able to state how much of the EM square the glyph should consume. To answer this question, I choose some characters that give me good approximations for baseline and cap-height - I need coverage on all lines of the original image, so am forced to include lower-case, numerical and symbolic characters as well the standard capitals.
baseline_chars = ['a' 'e', 'm', 'A', 'E', 'M', '&', '@', '.', u'≪', u'É']
caps_chars = ['M', 'A', 'E', 'k', 't', 'l', 'b', 'd', '1', '2', u'3', u'≪', '?', '!']
Using these, I keep track of the y positions for pertinent baselines and cap-heights for a given line:
line_stats = {}
for line, position, bbox, fname, chars in characters:
if len(chars) == 1:
this_line = line_stats.setdefault(line, {})
char = chars[0]
if char in baseline_chars:
this_line.setdefault('baseline', []).append(bbox[3])
if char in caps_chars:
this_line.setdefault('cap-height', []).append(bbox[1])
The following functions define the scaling and translation of the glyphs according to their relative position in the original handwriting sample. The functions are somewhat dense, and you'd be forgiven for not actually reading them...
from __future__ import division
import numpy as np
import psMat
def scale_glyph(char, char_bbox, baseline, cap_height):
# TODO: The code in this function is convoluted - it can be hugely simplified.
# Essentially, all this function does is figure out how much
# space a normal glyph takes, then looks at how much space *this* glyph takes.
# With that magic ratio in hand, I now look at how much space the glyph *currently*
# takes, and scale it to the full EM. On second thoughts, this function really does
# need to be convoluted, so maybe the code isn't *that* bad...
font = char.font
# Get hold of the bounding box information for the imported glyph.
import_bbox = c.boundingBox()
import_width, import_height = import_bbox[2] - import_bbox[0], import_bbox[3] - import_bbox[1]
# Note that timportOutlines doesn't guarantee glyphs will be put in any particular location,
# so translate to the bottom and middle.
target_baseline = char.font.descent
top = char.font.ascent
top_ratio = top / (top + target_baseline)
y_base_delta_baseline = char_bbox[3] - baseline
width, height = char_bbox[2] - char_bbox[0], char_bbox[3] - char_bbox[1]
# This is the scale factor that font forge will have used for normal glyphs...
scale_factor = (top + target_baseline) / (cap_height - baseline)
glyph_ratio = (cap_height - baseline) / height
# A nice glyph size, in pixels. NOTE: In pixel space, cap_height is smaller than baseline, so make it positive.
full_glyph_size = -(cap_height - baseline) / top_ratio
to_canvas_coord_from_px = full_glyph_size / font.em
anchor_ratio = (top + target_baseline) / height
# pixel scale factor
px_sf = (top + target_baseline) / font.em
frac_of_full_size = (height / full_glyph_size)
import_frac_1000 = font.em / import_height
t = psMat.scale(frac_of_full_size * import_frac_1000)
c.transform(t)
def translate_glyph(c, char_bbox, cap_height, baseline):
# Put the glyph in the middle, and move it relative to the baseline.
# Compute the proportion of the full EM that cap_height - baseline should consume.
top_ratio = c.font.ascent / (c.font.ascent + c.font.descent)
# In the original pixel coordinate space, compute how big a nice full sized glyph
# should be.
full_glyph_size = -(cap_height - baseline) / top_ratio
# We know that the scale of the glyph is now good. But it is probably way off in terms of x & y, so we
# need to fix up its position.
glyph_bbox = c.boundingBox()
# No matter where it is currently, take the glyph to x=0 and a y based on its positioning in
# the original handwriting sample.
t = psMat.translate(-glyph_bbox[0], -glyph_bbox[1] + ((baseline - char_bbox[3]) * c.font.em / full_glyph_size))
c.transform(t)
# Put horizontal padding around the glyph. I choose a number here that looks reasonable,
# there are far more sophisticated means of doing this (like looking at the original image,
# and calculating how much space there should be).
space = 20
scaled_width = glyph_bbox[2] - glyph_bbox[0]
c.width = scaled_width + 2 * space
t = psMat.translate(space, 0)
c.transform(t)
font = basic_font()
font.ascent = 600;
for line, position, bbox, fname, chars in characters:
c = create_char(font, chars, fname)
# Get the linestats for this character.
line_features = line_stats[line]
scale_glyph(
c, bbox,
baseline=np.mean(line_features['baseline']),
cap_height=np.mean(line_features['cap-height']))
translate_glyph(
c, bbox,
baseline=np.mean(line_features['baseline']),
cap_height=np.mean(line_features['cap-height']))
# Simplify, then put the vertices on rounded coordinate positions.
c.simplify()
c.round()
# Take a look at this refined font.
font.generate(font_fname)
preview_content = u"""\
Hello world!! Testing some ligatures: BETTER;
XKCD IS OFTEN IN *CAPITALS*, SO IT'S (SEMI-) IMPORTANT TO GET IT "RIGHT"...!?!
Can one really have their 🎂 AND eat it, I wonder. Hmmm caaake! 🎂 Cool.
C:\\\\ 12345 (6+8)/2=7 </html> @ http://fooj.com/under_score/dash-dot."""
display(preview_font(font_fname, content=preview_content))
Really not too shabby... some attention to detail is needed now though. There are a number of issues with this font that I think are readily addressable:
- I really dislike the capital C and G - they come from the prose part of the sample handwriting dataset, and I'd rather use the glyphs from the alphabet line above for these particular characters
- The spacing on the ligatures is better, but not perfect. The point of the ligatures is to make the characters flow smoothly, and there is simply too much space between the "TT" and "ER" of "BETTER".
- The spacing on the lower case "g" and "j" could do with some work.
- The kerning on the capital "T" and lower case "r" (when followed by "e") need some work.
- The slashes (both forward and back) when paired could do with being closer together.
The finished article¶
The biggest issue I had with the previous attempt was related to glyph spacing. For that reason, I'm going to focus on kerning, which is essentially a place for special case spacing between character pairs. All the advice I've read about kerning is that it is necessary, but should be used sparing (in favour of improved glyph horizontal space).
In order to add kerning to the font, I need to add a kerning lookup table, and a subtable to hold the kern pairs. I can then ask fontforge to determine sensible kerning pairs based on the space that I'd like to have between the character groups.
def autokern(font):
# Let fontforge do some magic and figure out automatic kerning for groups of glyphs.
all_glyphs = [glyph.glyphname for glyph in font.glyphs()
if not glyph.glyphname.startswith(' ')]
ligatures = [name for name in all_glyphs if '_' in name]
upper_ligatures = [ligature for ligature in ligatures if ligature.upper() == ligature]
lower_ligatures = [ligature for ligature in ligatures if ligature.lower() == ligature]
caps = list('ABCDEFGHIJKLMNOPQRSTUVWXYZ') + upper_ligatures
lower = list('abcdefghijklmnopqrstuvwxyz') + lower_ligatures
all_chars = caps + lower
# Add a kerning lookup table.
font.addLookup('kerning', 'gpos_pair', (), [[b'kern', [[b'latn', [b'dflt']]]]])
font.addLookupSubtable('kerning', 'kern')
# Everyone knows that two slashes together need kerning... (even if they didn't realise it)
font.autoKern('kern', 150, ['slash', 'backslash'], ['slash', 'backslash'])
font.autoKern('kern', 60, ['r', 's'], lower, minKern=50)
font.autoKern('kern', 100, ['f'], lower, minKern=50)
font.autoKern('kern', 180, all_chars, ['j'], minKern=35)
font.autoKern('kern', 150, ['T', 'F'], all_chars)
font.autoKern('kern', 30, ['C'], all_chars)
font = basic_font()
font.ascent = 600;
# Pick out particular glyphs that are more pleasant than their latter alternatives.
special_choices = {('C', ): dict(line=4),
('G',): dict(line=4),
# Get rid of the "as" ligature - it's not very good.
('a', 's'): dict(line=None),
# A nice tall I.
('I', ): dict(line=4)}
for line, position, bbox, fname, chars in characters:
if chars in special_choices:
spec = special_choices[chars]
spec_line = spec.get('line', any)
if spec_line is not any and spec_line != line:
continue
c = create_char(font, chars, fname)
# Get the linestats for this character.
line_features = line_stats[line]
scale_glyph(
c, bbox,
baseline=np.mean(line_features['baseline']),
cap_height=np.mean(line_features['cap-height']))
translate_glyph(
c, bbox,
baseline=np.mean(line_features['baseline']),
cap_height=np.mean(line_features['cap-height']))
# Simplify, then put the vertices on rounded coordinate positions.
c.simplify()
c.round()
autokern(font)
font.generate(font_fname)
display(preview_font(font_fname, content=preview_content, unique_id='final'))
What's missing?¶
First up, I want to remind myself what the current version of the XKCD font looks like (taken from SHA 5a662e1 of ipython/xkcd-font):
original_font_fname = os.path.expanduser('~/Downloads/xkcd-Regular.otf')
content = "This is the original font, not the one I've created:\n" + preview_content
display(preview_font(original_font_fname, content=content))
This font is far more regular in its vertical alignment, but in reality the original handwriting sample that my work is based upon is far from regular.
Obviously there are some issues with the font weight from this version - it is particularly stark for caps vs lower case characters, but even within these groups there are obvious issues. In the URL example, the lowercase "j" seems to be scaled poorly, and the lowercase "u", "n" and "d" are very different in appearance (scale and thickness).
Having taken a look at this, I'm very pleased with how my work has turned out. My remaining question is whether there are any glyphs in the original font that aren't in mine?
original_font = fontforge.open(original_font_fname)
original_glyphs = set([glyph.glyphname for glyph in original_font.glyphs()])
new_glyphs = set([glyph.glyphname for glyph in font.glyphs()])
missing_glyphs = sorted(original_glyphs - new_glyphs)
print('Missing glyphs in new font: {}'.format(', '.join(missing_glyphs)))
missing_chars = []
for glyph_name in missing_glyphs:
glyph = original_font[glyph_name]
if glyph.unicode > 0:
missing_chars.append(unichr(glyph.unicode))
display(
preview_font(
original_font_fname,
content='Missing chars: ' + ' '.join(missing_chars)))
It seems that some of these may be useful, but I don't currently know how to easily copy a glyph from one font file to another (it should be achievable by exporting the contours, and then re-importing them, but that sounds like hard work for not a huge amount of benefit). If you know how to do it easily, you might consider answering https://superuser.com/q/334971/452816 and letting me know in the comments.
Wrap-up¶
So that is the end of my XKCD font saga (for now at least). I've learnt a huge amount along the way and strongly encourage this kind of exploration as a means of learning new (and unexpected!) things. On this journey I've learnt:
- How to use scipy & scikit-image's image labeling functionality to classify distinct features in an image, and to extract them as separate entities for further processing
- How to convert raster images (PPM) into SVGs using potrace
- How to compile FontForge on OSX
- How to create a basic font with FontForge's scripting tools
- How to embed a web font as base64 object in a webpage (in this case, the Jupyter Notebook interface)
- A whole heap about Fonts, including the EM square, ligatures and kerning
- Patience - because finding out most of this stuff has been trial and error!
I'm really pleased with the outcome of this investigation, and will be turning all of this work into a PR on the ipython/xkcd-font repo. I'm hopeful that my improvements to the font will be beneficial to all the XKCD lovers out there - I'm particularly excited about using it in my matplotlib figures (who am I kidding, I'm excited about using it everywhere!).
Enjoy!!! :)